![]()
Visualisation avec les données en sortie d’ezPAARSE
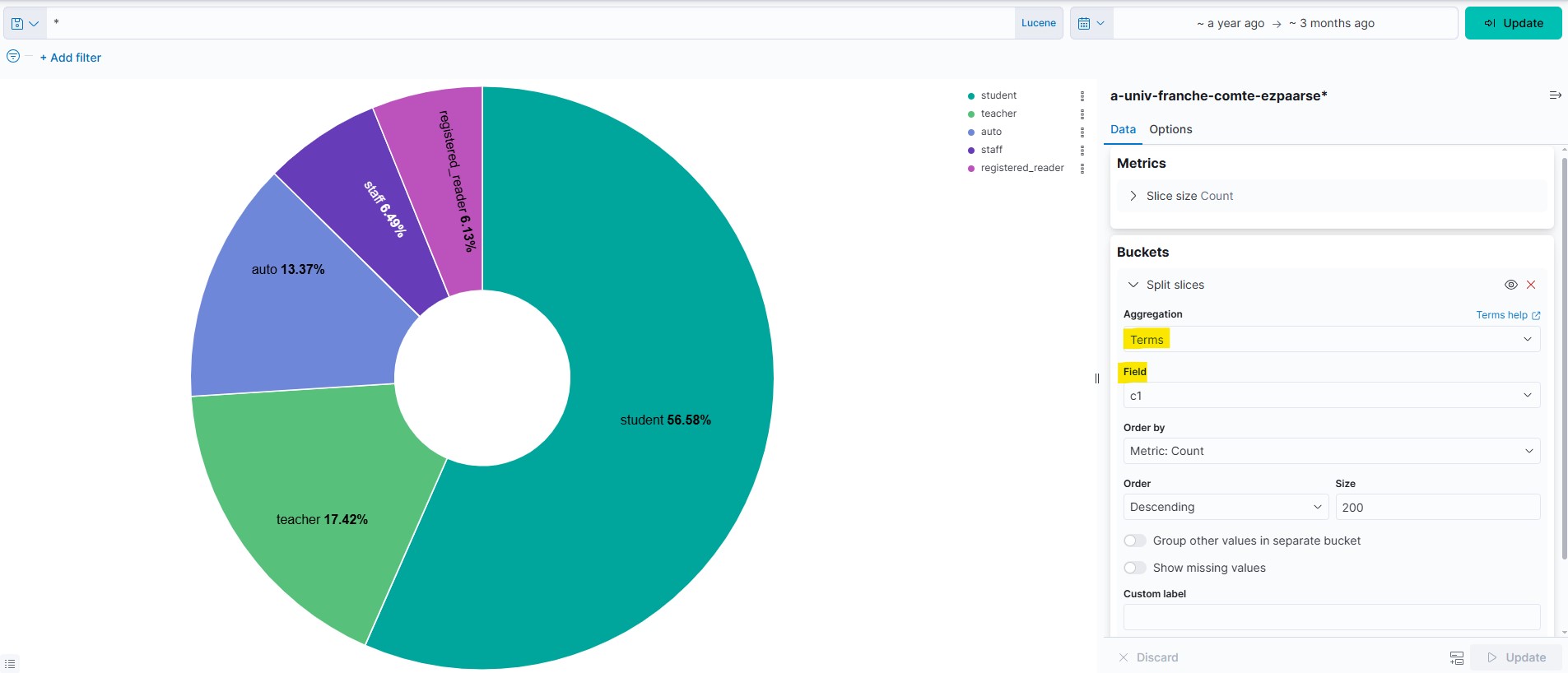
Dans cette image, nous avons une visualisation camembert (Pie chart) avec un découpage agrégé sur le champ (Terms) « c1.keyword ». On peut voir en haut à droite les données brutes issues des événements de consultations (ECs). Ici les libellés sont en anglais, car c’est ainsi qu’ils apparaissent dans les fichiers logs traités par ezPAARSE pour cet établissement.
Il est possible d’établir la même visualisation en modifiant les libellés des données et permettre une meilleure lisibilité du tableau de bord.
Visualisation avec filtrage des données et modification des libellés
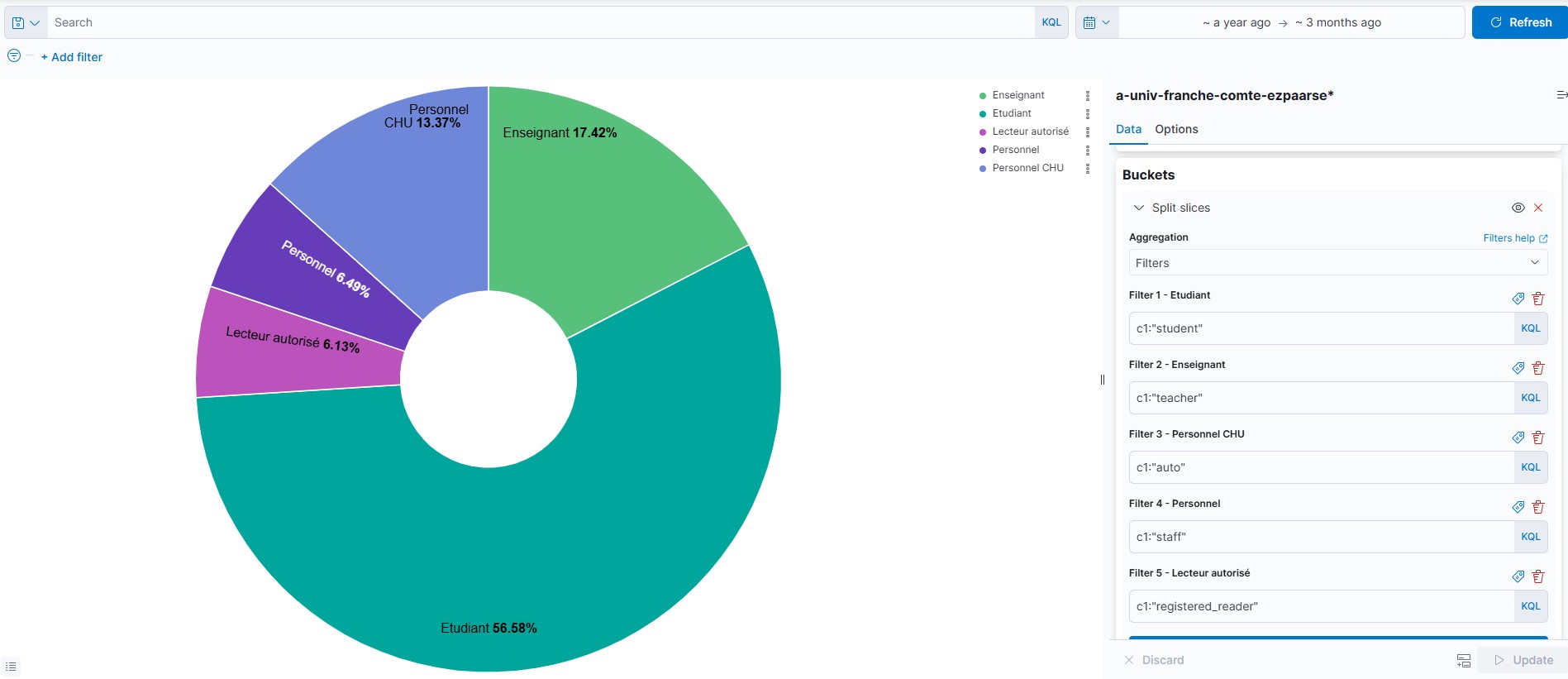
Comme le montre l’image ci-dessus, il faut remplacer dans l’emplacement « Split Slices » l’agrégation « Terms » par « Filters« , c’est-à-dire que nous allons appliquer un ou plusieurs filtres pour rechercher les données directement dans l’index. Dans l’exemple, nous demandons :
c1:student (le champ c1 contenant student)
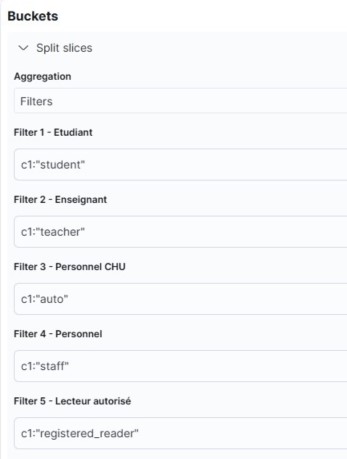
et nous lui attribuons le libellé (label) « Etudiants ». Il y a une petite étiquette blanche sur fond gris pour écrire ou modifier un libellé et une croix rouge pour le supprimer.
Chaque filtre se présente comme une query (une requête) et il est possible de faire une agrégation sur plusieurs données en utilisant un opérateur booléen (ici : « OR »).
Nous procédons de la même façon pour les autres champs que l’on souhaite afficher : pour ajouter un filtre, il suffit de cliquer sur « Add filter ».
Enfin, quand on clique sur la petite flèche bleue, nous obtenons notre camembert avec les agrégations demandées et des libellés lisibles.

Evolution de Kibana version 7.4 (novembre 2020)
Kibana a évolué depuis la rédaction de ce tutoriel.
Le principe des filtres ne change pas tel qu’il est présenté dans le premier paragraphe.
En revanche, le mode de saisie d’un filtre est plus simple, car la query est en mode auto-complétion :
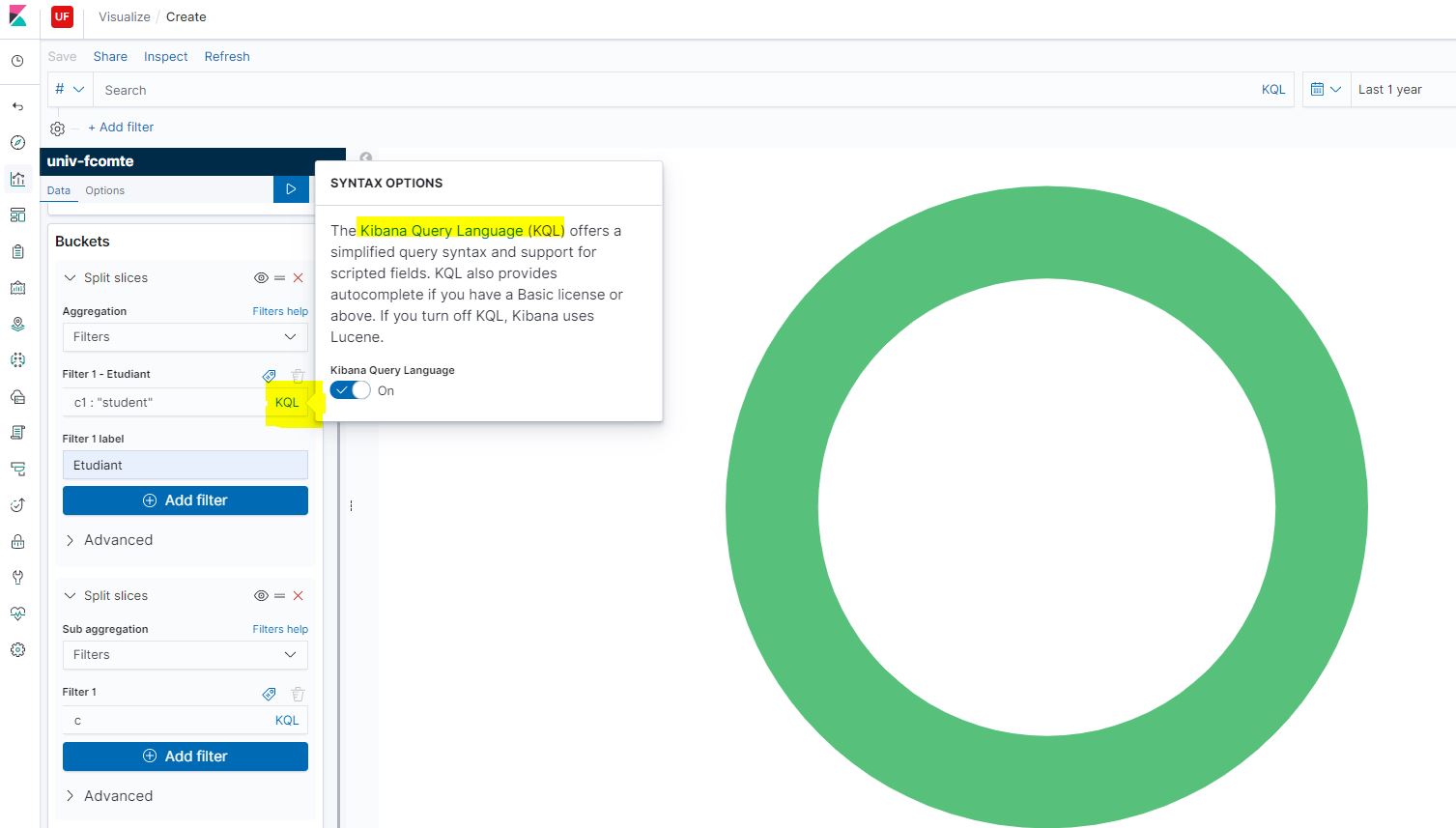
Dans le champ filter, on a l’indication KQL (Kibana Query Language) qui vous rédige la query de façon intuitive.
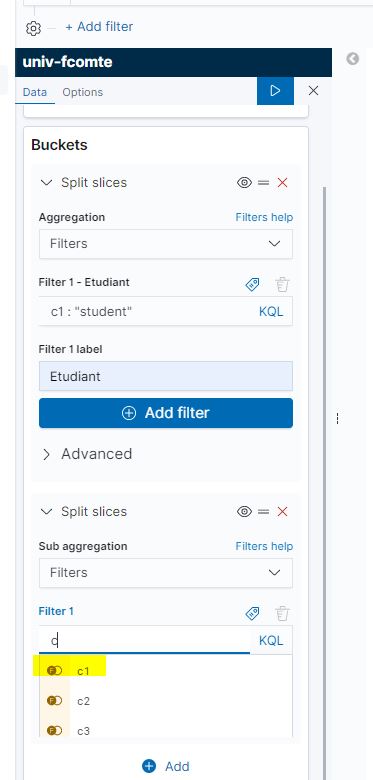
Saisie du champ recherché (la première lettre permet d’obtenir 3 propositions de champ à sélectionner). Dans l’exemple, c’est C1 qui est demandé.
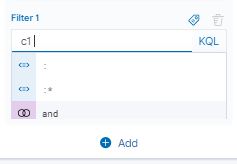
Kibana vous propose ensuite l’opérateur booléen, ici, c’est « : »
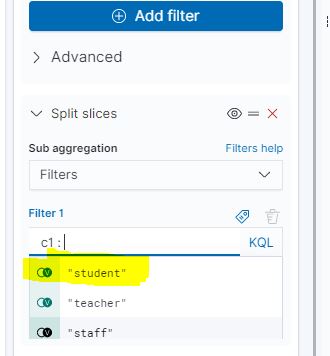
Ensuite, c’est la valeur du champ qu’il faut sélectionner, ici, « student ».
C’est très pratique dans le cas d’un grand nombre de filtres et cela évite les erreurs de saisies qui peuvent fausser les résultats.
On peut appliquer la même méthode à n’importe quel champs contenant des données que l’on souhaite rendre plus explicite. C’est un cas d’utilisation très simple que je vous invite à tester vous-même.
Si vous souhaitez réaliser des visualisations avec des requêtes plus complexes, n’hésitez pas à nous consulter et nous essaierons de trouver des solutions à vos besoins.
Bonne journée.
Frédéric pour ezTEAM